Википедия является многоязычной общедоступной свободно распространяемой энциклопедией. Ее созданием занимаются многочисленные авторы со всего мира, которые пользуются технологией вики. С момента возникновения в начале 2001 года и до сих пор Википедия постоянно пополняется и завоевывает популярность.
Википедию считают самой полной энциклопедией, которая была когда-либо создана, так как она имеет большой объем сведений и огромный тематический охват. Одним из преимуществ Википедии является предоставление информации на родном языке без каких-либо ценных потерь в аспекте культурной принадлежности.
Все статьи в энциклопедии создаются непосредственно самими пользователями, к тому же каждый пользователь может редактировать абсолютно любую статью. В данный момент Википедия является одним из десяти самых посещаемых сайтов в мире.
История Википедии
В 1999 году проект Everything2 впервые предоставил своим пользователям возможность редактирования любого содержимого на сайте, но основатели и не надеялись создать какую-то серьезную энциклопедию.
Вот поэтому прародителем Википедии считается Нупедия – англоязычный проект энциклопедии, который реализовал принципы свободы информации. Написанием статей для Нупедии занимались ученые и академики, а непосредственными основателями считаются Джимми Уэйлс – на тот момент являлся исполнительным директором компании Bomis, он и финансировал данный проект, а также Лоуренс Сэнгер – организатор и главный директор проекта.
Джимми Уэйлс - идеолог Вики
Ларри Сэнгер
Для ускорения наполнения энциклопедии был открыт сайт «Википедия». Редактировать содержимое данного ресурса с этого момента мог практически каждый пользователь Интернета. Уже в мае того же года Википедия запустила новые языковые разделы – японский, иврит, каталанский, эсперанто, португальский, испанский, итальянский, французский, шведский, немецкий, русский, а также венгерский и арабский. На сегодняшний день в Википедии установлено 264 языковых раздела.
Что значит слово «вики"?
Вики – это сайт, содержимое которого пользователи могут самостоятельно изменять с помощью инструментов, предоставляемых самим сайтом. Форматирование текста и вставка различных объектов в текст производится с использованием вики-разметки.
Впервые термин «вики» для описания веб-сайта был использован в 1995 году Уордом Каннингемом, разработчиком первой вики-системы WikiWikiWeb. Он заимствовал слово гавайского языка, означающее «быстрый». Каннингем объяснил выбор названия движка тем, что он вспомнил работника международного аэропорта Гонолулу, посоветовавшего ему воспользоваться вики-вики шаттлом — небольшим автобусом, курсировавшим между терминалами аэропорта.
Автобус в аэропорту Гонолулу
Правила вики-разметки:
Действие
Вики-разметка
Создать статью
[[Название_новой_статьи]]
Дать ссылку на статью
[[Название_статьи_в_Вики текст_ссылки]]
Дать ссылку на внешний ресурс
[URL-адрес_ресурса текст ссылки]
Вставить картинку
Загрузить картинку на Вики, затем [Файл:Название_картинки|раз мер_картинки|подпись_под_картинкой]
Создать заголовок
==Заголовок1_1_уровня==
===Заголовок_2_уровня===
====Заголовок_3_уровня===
Создать галерею рисунков
<gallery>
Файл: Название_загруженного_файла1
Файл: Название_загруженного_файла2
…
</gallery>
Использовать шаблон для создания страницы
Вставить в поле редактора страницы {{код_шаблона}}
Технологии Web 2.0 – это методика проектирования систем, которые путём учёта сетевых взаимодействий становятся тем лучше, чем больше людей ими пользуются.
Особенностью Web 2.0 является принцип привлечения пользователей к наполнению и многократной выверке информационного материала.
Ввел этот термин Тим О’Рейли, сотрудник Google, в 2005 году. В статье «Tim O’Reilly — What Is Web 2.0» Тим О’Рейли увязал появление большого числа сайтов, объединённых некоторыми общими принципами, с общей тенденцией развития интернет-сообщества, и назвал это явление Веб 2.0, в противовес «старому» Веб 1.0.
Тим О`Рэйли, идеолог Web 2.0
Рекомендую вам интервью Тима О`Рэйли, в котором он рассуждает на тему того, показывать ли YouTube пришельцам, нормально ли делать деньги на людях, которым не платят за их труд – и почему он устал от термина «Веб 2.0».
Три этапа развития сети
Web 1.0, 2.0, 3.0 — это, можно сказать, условные исторические этапы, которые выделяют в развитии Всемирной паутины. Переход между ними нельзя привязать к конкретной дате или даже году, так как он происходит медленно и оставляет многое из предыдущих этапов. Выделение этих этапов может быть достаточно спорным.
Технологии, особенности создания сайтов и поведение пользователей Всемирной паутины (WWW), характерные для 90-х и начала 2000-x годов, принято называть Веб 1.0 (Web 1.0). В этот период в WWW преобладали статичные сайты. Такие сайты предназначались в основном для чтения, получения информации; не считая гиперссылок, они почти не содержали интерактивных элементов, мультимедиа, не предоставляли возможности пользователям вести диалог, обмениваться файлами и т. п.
Для создания сайтов использовался ряд тегов языка разметки HTML, не отвечающих за разметку как таковую, а выполняющих оформительскую функцию. Часто разметка сайта делалась за счет создания таблиц на языке HTML. Все это делало код страницы «грязным» и большим, сложным для чтения поисковыми роботами.
Во времена Web 1.0 преобладали медленные типы подключения к сети, поэтому многие ограничения были вызваны этим фактом. Так, например, видео во Всемирной паутине было редким явлением. Для общения пользователей организовывались форумы и чаты.
Где-то примерно в середине 2000-x методы и цели создания сайтов начали меняться. Появилась ориентация на динамическое создание содержания, когда пользователи сами наполняют ресурс, общаются между собой и высказывают мнения прямо на сайте. Начали появляться блоги, социальные сети, wiki-проекты. На сегодняшний день такая форма организации и создания контента занимает существенную долю WWW, а пользуются такими сайтами большинство пользователей Интернета.
С появлением высокоскоростного доступа к сети Интернет во Всемирной паутине стала популярной мультимедиа информация (видео, музыка, графика).
Сравнение этапов Web 1.0 и Web 2.0
Веб 2.0 отмечается появлением новых веб-служб, развитием web-программирования, улучшением дизайна и удобства сайтов, уменьшением возможности пользователя быть анонимным.
Несмотря на явное преимущество Веб 2.0, следует отметить появление во Всемирной паутине большого количества некачественной информации, в том числе дезинформации. Поэтому, независимо от технологий, лежащих в основе создания сайта, в первую очередь ценится его информационное наполнение. На сегодняшний день найти качественную информацию в сети среди огромного ее количества не так просто.
Ресурсы, использующие Web 2.0:
Блоги
Вики-ресурсы
Социальные сети
Документы совместного доступа
Группы
Социальные сервисы
Сервисы Web 2.0
Идею Веб 3.0 можно сформулировать, как избавление от недостатков 2.0. Уделяется особое внимание качеству сервисов и контентов, управление и наполнение информацией передается в руки профессионалов. Однако данная концепция имеет уже другие недостатки, связанные со все увеличивающейся невозможностью пользователя оставаться анонимным, подчинению его определенным правилам веб-сервисов и др. Сайт, идеологически близкий к Web 3.0, можно представить как интернет-сервис, предоставляемый организацией. Примером таких сервисов могут служить облачные технологии, навигация по картам местности.
Облачные технологии
В отличие от модели хранения данных на собственных выделенных серверах, количество или какая-либо внутренняя структура серверов клиенту не видна.
Данные хранятся и обрабатываются в так называемом облаке, которое представляет собой, с точки зрения клиента, один большой виртуальный сервер. Физически же такие серверы могут располагаться удалённо друг от друга географически, вплоть до расположения на разных континентах.
Схема работы облачных сервисов
В чем преимущества использования Веб 2.0?
Веб-служба находится на серверах компании, которая её создала, поэтому в любой момент пользователю доступна самая свежая версия данных и ему не приходится заботиться об обновлениях
Социализация сайта, то есть возможность индивидуальных настроек сайта и создание личной зоны (личные файлы, изображения, видео, блоги)
Использование возможностей «коллективного разума», при этом добавляется соревновательный элемент
Недостатки Web 2.0
зависимость сайтов от решений сторонних компаний
уязвимость конфиденциальных данных, хранимых на сторонних серверах, для злоумышленников (известны случаи хищения личных данных пользователей, массовых взломов учётных записей блогов);
«затопление вздором» (английский термин BS-flooding).
сбор статистики о пользователях, их предпочтениях и интересах, личной жизни, карьере, круге друзей могут помочь владельцу сайта манипулировать сообществом
Подробнее читайте в презентации к уроку. Интернет-мем – это явление спонтанного распространения некоторой информации или фразы, часто бессмысленной, спонтанно приобретшей популярность в интернет-среде посредством распространения в интернете всеми возможными способами (по электронной почте, в мессенджерах, форумах, блогах и др.), также сама эта информация или фраза.
Традиционно подобным образом распространялись анекдоты. Но специальное внимание на явление, названное затем «интернет-мемами», обратили, когда по тому же принципу стали распространяться вещи, на традиционные анекдоты и развлечения не похожие.
Мемом может считаться любая идея, символ, манера или образ действия, осознанно или неосознанно передаваемые от человека к человеку. Концепция мема и сам термин были предложены эволюционным биологом Ричардом Докинзом в 1976 году в книге «Эгоистичный ген». Докинз предложил идею о том, что вся культурная информация состоит из базовых единиц — мемов, точно так же как биологическая информация состоит из генов.
Главная способность мема- вызывать эмоции. Мемы вызывают эмоциональную реакцию. Причем довольно часто - с негативным, провокационным “тинэйджерским” оттенком. Часто это может быть смех, некое пренебрежение, неприятие, сарказм, явный или скрытый страх. Эмоционально окрашенная информация лучше обращает на себя внимание. Эмоции (в данном случае – неважно какие) являются важным фактором для первоначального запоминания мема и стимулом для дальнейшего его распространения и осмысления.
Распространение мема лишь внешне выглядит как передача от человека к человеку непосредственно содержащейся в нем информации. Действительно, внешне распространение мема выглядит именно как передача бессодержательной забавной информации-пустышки. В случае популярного мема передается не сама информация, а знак, указывающий на нечто, помимо мема давно существующее и по разным причинам длительное время не попадающее в зону общественного осознания.
Для успеха мема необязательно его понимание. Хороший мем воздействует частично на подсознательном уровне, когда человек до конца не понимает, что именно его смешит в меме, сердит или раздражает. Эмоционально-провокационная форма делает мем лучше запоминающимся, эмоционально окрашенный мем быстрее обдумывается. Первоначально мем “вцепляется” в память, а затем – человек сам приходит к той или иной степени его понимания.
2 фаза: изображение чучела лиса начинает появляться в любительских фотоколлажах. Смех вызывает внезапное появление лиса на узнаваемом фоне. Фон играет большую роль, чем появление на нем лиса.
3 фаза: Возникает эпитет "упоротый". Упоротый лис появляется, неся одну из идей-ассоциаций:
Безысходности, тоски;
Особого отстраненного и задумчивого состояния, настроения;
Состояния наркотического опьянения
4 фаза: Упоротый лис на этой стадии оформляется в самостоятельный мем. Мем становится источником для Интернет-фольклора.
Медиавирусы - распространяющиеся по инфосфере мемы и мемокомплексы, чья информация изменяет восприятие людьми локальных и глобальных событий. Этот термин введён американским специалистом в области средств массовой информации Дугласом Рашкоффом для обозначения медиасобытий, вызывающих прямо или косвенно определённые изменения в жизни общества.
Виды медиавирусов:
Преднамеренно созданные медиавирусы, сознательно кем-то запускаемые, чтобы способствовать распространению какого-либо товара или идеологии. Примеры: рекламные трюки
«Кооптированные» вирусы, или «вирусы-тягачи», которые могут возникнуть спонтанно, но мгновенно утилизируемые заинтересованными группами с целью распространения собственных концепций. Примеры: публичные скандалы вокруг звезд
Полностью самозарождающиеся вирусы — медиавирусы, вызывающие интерес и распространяющиеся сами по себе. Пример: навязчивые мелодии.
Лера Поддубная и Дима Ясманович участвуют в конкурсе проектов "Відновлення мого місця проживання" с видео "Школа адаптации". Поддержите их, поставив лайк под видео!
Просмотрите эти страницы ВКонтакте и найдите данные. которые могут представлять угрозу безопасности пользователей:
http://vk.com/olia_zabun.official
http://vk.com/minindenis
http://vk.com/fukkacumi
https://vk.com/mikonoriko
Подробнее с угрозами безопасности вы сможете познакомиться в презентации к уроку.
В интернете действует принцип презумпции небезопасности, то есть всякая программа считается небезопасной, пока не доказано обратное. Каждый лично сам определяет для себя границы достаточной безопасности. Но полной безопасности при работе в интернете обеспечить невозможно.
Отсутствие безопасности или недостаточную безопасность называют уязвимостью.
Уязвимостей на компьютере может быть великое множество, но у всех одна природа – программное обеспечение.
Источники уязвимости:
1. Недокументированные функции
В программах могут быть такие функции, о которых, по мнению разработчиков, нам знать не положено. Особую опасность представляет ситуация, когда ОС, браузер и почтовый клиент выпущены одной фирмой
2. Имплантанты
Это специальные программы или расширения программ, которые мы устанавливаем сами или которые устанавливаются нелегально – так называемое шпионское ПО (SpyWare, AdWare)
3. Средства удаленного администрирования
Удаленное администрирование – это взятие чужого компьютера под свое управление. Для этого надо подкинуть на компьютер небольшую программу серверного типа – так называемый троянец.
Если троянец проник на жесткий диск, то обнаружить его можно при попытке установить связь со злоумышленником
Хакер обращается наугад по множеству IP-адресов в ожидании отклика. Эта процедура называется сканированием IP-адресов. Чтобы зафиксировать момент подключения, используются программы - файрволлы
4. Ошибки программного кода
Уязвимостями браузера пользуются, чтобы получить несанкционированную информацию или взять компьютер под удаленный контроль.
5. Маркеры cookies
Это маленькие текстовые файлы, которые сервер отправляет пользователю, чтобы выделить старых клиентов и отличать их от новых. Они хранятся в папке C:\Windows\Cookies. Для удаления лучше использовать специальные программы, например InterMute
6. Активные объекты
Для расширения возможностей взаимодействия браузера и веб-сервера многие создатели веб-страниц встраивают в них так называемые активные компоненты, в которых содержится программный код. Наиболее распространены два типа – апплеты Java и элементы ActiveX.
Основным назначением Adware является получение прибыли и покрытие расходов на разработку программного обеспечения (например, конвертора видео или клиента системы мгновенных сообщений). Таким образом Adware — это неявная форма оплаты за использование программного обеспечения, осуществляющаяся за счёт показа пользователю рекламной информации.
Что делает Adware?
устанавливаются без согласия пользователя
показывают рекламные заставки, базирующиеся на результатах шпионской деятельности на компьютере
демонстрируют всплывающие окна с рекламой
запоминают информацию о веб-сайтах, посещаемых пользователем. Данные используются для целевого рекламного эффекта
8. Spyware
- программное обеспечение, осуществляющее деятельность по сбору информации о конфигурации компьютера, деятельности пользователя и любой другой конфиденциальной информации без согласия самого пользователя.
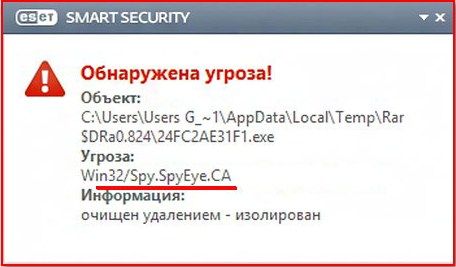
Обнаружение шпионской программы с помощью Eset NoD 32
Задачи Spyware:
собирать информацию о посещаемых веб-сайтах в Интернете и используемом программном обеспечении;
запоминать нажатия клавиш на клавиатуре и записывать скриншоты экрана;
проводить анализ состояния систем безопасности.
в дальнейшем вся собранная информация отправляется разработчикам шпионского программного обеспечения
Один из путей проникновения шпионских программ - скрытая установка. Пользователь сам дает согласие на установку, не читая лицензионное соглашение
Как они проникли на ваш компьютер?
их может загрузить и установить троянец
при открытии веб-страницы в зависимости от настроек вашего браузера у вас могут попросить разрешение на установку ActiveX компонента из небезопасного и непроверенного источника. Если вы согласитесь, то они будут установлены
скрыто в процессе установки на первый взгляд безвредных программ, скачанных из Интернета с условно-бесплатной или бесплатной лицензией.
Изготовители spyware заявляют, что пользователи на самом деле дают согласие на инсталляцию! Spyware, поставляемое в комплекте с дистрибутивом, может быть упомянуто в пользовательском соглашении. Однако большинство пользователей по привычке игнорируют прочтение документа и просто нажимают кнопку «Согласен».
Социальная инженерия — это метод управления действиями человека без использования технических средств. Метод основан на использовании слабостей человеческого фактора и считается очень разрушительным.
Ввел этот термин осуждённый компьютерный преступник и консультант по безопасности Кевин Митник, заявивший, что для злоумышленника гораздо проще хитростью выудить информацию из системы, чем пытаться взломать её.
Часто социальную инженерию рассматривают как незаконный метод получения информации.
Однако это не совсем так. Социальную инженерию можно также использовать и в законных целях, и не только для получения информации, а и для совершения действий конкретным человеком.
Сегодня социальную инженерию зачастую используют в интернете, для получения закрытой информации, или информации, которая представляет большую ценность.
Подробнее о методах социально инженерии смотрите в видео:
Подробнее вы можете познакомиться с теорией в презентации к уроку. Электронная почта — сервис по пересылке и получению электронных сообщений по сети.
Электронная почта по составу элементов и принципу работы практически повторяет систему обычной (бумажной) почты, заимствуя как термины (почта, письмо, конверт, вложение, ящик, доставка и другие), так и характерные особенности— простоту использования, задержки передачи сообщений, достаточную надёжность и в то же время отсутствие гарантии доставки.
Немного об истории электронной почты и ее создателе Рэе Томлисоне смотрите в видео:
Достоинствами электронной почты являются:
легко воспринимаемые и запоминаемые человеком адреса вида имя_пользователя@имя_домена (например, somebody@example.com);
возможность передачи как простого текста, так и форматированного, а также произвольных файлов;
независимость серверов (в общем случае они обращаются друг к другу непосредственно);
достаточно высокая надёжность доставки сообщения;
простота использования человеком и программами.
Недостатки электронной почты:
наличие такого явления, как спам (массовые рекламные и вирусные рассылки); теоретическая невозможность гарантированной доставки конкретного письма;
возможные задержки доставки сообщения (до нескольких суток);
ограничения на размер одного сообщения и на общий размер сообщений в почтовом ящике (персональные для пользователей).
В электронной почте e-mail используют не один прикладной протокол, как в других службах Интернета, а два. По одному протоколу происходит отправка почты, а по другому — ее прием. Необходимость в двух протоколах связана с требованиями безопасности. Так, например, при отправке сообщений можно не проверять личность отправителя — это аналогично тому, что письмо брошено в уличный почтовый ящик. Другое дело — получение сообщений. Здесь надо предъявить свои права и пройти идентификацию. Так, например, при получении заказных писем в почтовом отделении всегда необходимо предъявить паспорт или заменяющий его документ. Кому попало чужую почту в руки не отдадут.
Для отправки на сервер и для пересылки между серверами используют протокол, который называется SMTP (Simple Mail Transfer Protocol — простейший протокол передачи сообщений). Он не требует идентификации личности.
Для получения поступившей почты используется протокол РОРЗ (Post Office Protocol 3 — протокол почтового отделения, версия 3). Он требует идентификации личности, то есть должно быть предъявлено регистрационное имя (Login) и пароль (Password), который подтверждает правомочность использования имени.
Протоколы SMTP и POP3 являются прикладными протоколами, т.е. они надстроены над базовыми протоколами Интернета TCP/IP.
Почтовый клиент — программа, предназначенная для получения, написания и хранения электронной почты.
Окно почтового клиента The Bat!
Самые популярные почтовые клиенты:
Mozilla Thunderbird — современная программа для работы с электронной почтой. Поддерживает протоколы SMTP, POP3, IMAP, RSS. Thunderbird работает в операционных системах: Windows, Mac OS X и Linux. Программа имеет простой, гибко настраиваемый интерфейс.
The Bat! — одна из наиболее удачных и мощных программ для работы с электронной почтой. Позволяет работать с неограниченным количеством почтовых ящиков (протоколы POP3, IMAP4, SMTP и APOP), имеет настраиваемую систему фильтров, редактор текста с форматированием, а также умеет проверять орфографию.
Outlook Express и Windows Mail — стандартные программы для работы с электронной почтой от всем известной компании Microsoft. Outlook Express поставляется в составе операционных систем Windows XP, Windows Mail — в составе Windows Vista.
На сегодня существует два вида электронной почты:
Классическая e-mail- использует почтовые протоколы и почтовые клиенты
Web-почта – обслуживается службой WWW
Классическая электронная почта имеет направленный характер. То есть в ней важно не местоположение конечного адресата, а маршрут перемещения письма. Следовательно, получить доступ к такому почтовому ящику пользователь сможет только на том компьютере, на котором установлен почтовый клиент, создавший его учетную запись
.
Этого недостатка лишена веб- почта. В качестве серверов веб- почты выступают обычные веб- серверы. Они работают в паре с базой данных и каждому клиенту формируют при подключении веб-страницу, соответствующую текущему состоянию его учетной записи в базе данных.
Web-mail, в отличие от e-mail, не является самостоятельной службой. Это просто еще один дополнительный сервис общей службы WWW
С точки зрения пользователя разница между ними может быть как громадной, так и незаметной вообще.
Интерфейс веб-почты Gmail
Преимущества веб-мейл:
Простота использования
Относительная анонимность
Мобильность
Простота управления учетной записью
И недостатки:
Непредставительность
Низкая скорость работы
Ограниченность полезных функций
Угроза безопасности
Проблемы с кодировками
Почтовая система позволяет организовать сложные системы, основанные на пересылке почты от одного ко многим абонентам.
Почтовые рассылки — письмо от одного адреса с одинаковым (или меняющимся по шаблону) содержимым, рассылаемое подписчикам рассылки.
Группы переписки — специализированный тип почтовой рассылки, в которой письмо на адрес группы (обычный почтовый адрес, обработкой почты которого занимается специализированная программа) рассылается всем участникам группы.
Непрошеные рассылки называются спамом. Спам — это рассылка коммерческой, политической и иной рекламы или иного вида сообщений лицам, не выражавшим желания их получать.
Виды спама:
Реклама
Реклама незаконной продукции
Антиреклама и клевета
«Нигерийские письма»
Фишинг
«Письма счастья»
Массовая рассылка для вывода почтовой системы из строя (DoS-атака).
Скетч группы "Монти Пайтон" о спаме:
Инфографика о спаме от Евгения Касперского (рисунок кликабелен, можно увеличить):
Поисковые каталоги представляют из себя справочники, в которых все сайты находятся в алфавитном или тематическом порядке. Отличием каталогов от поисковых систем является то, что каталоги не используют пауков, которые ищут странички по всему интернету.
В то время как поисковые машины принимают почти любые сайты, без требований к качеству, каталоги же, как правило, предъявляют требования к качеству и содержанию сайта. Так как в наиболее крупных и известных каталогах сайты проверяются людьми, то низкокачественные сайты не попадают в базу данных. В каталогах регистрируют обычно только главную страницу сайта (еще одно отличие от поисковиков).
История создания первого каталога
В 1994 году, студенты Стэндфордского университета, Джерри Янг и Дэвид Фило, готовились к защите диссертации в области компьютерного проектирования интегральных схем. Для этого им приходилось много времени проводить в сети Интернет, в поисках нужной информации и копить ссылки. Списки со ссылками росли, потом Янг и Фило забросили диссертацию и принялись исключительно коллекционировать ссылки. К середине 1994 года их стало много, они отсортировали ссылки по категориям, потом в категориях ссылок стало тоже много, появились подкатегории.
И кто бы мог подумать, что у самого успешного Интернет проекта www.yahoo.com собственный поиск появился совсем недавно! Но список Джерри и Дэвида не был предназначен для всеобщего обозрения - он составлялся исключительно для друзей. Время шло, а посещаемость все росла и росла. Адрес сайта пошел по рукам....
Первым шагом к успеху стало новое, запоминающееся название - Yahoo!. Следуя пожеланиям пользователей, создатели www.Yahoo.com, стали преобразовывать сайт. Появились новые категории, и разделы "What's New" и "What's Cool". К концу 1994 Янг и Фило забросили свои диссертации и полностью отдались работе над поисковиком Яху.
В это время на дороге появилась компания Netscape, предложившая ресурсы для содержания поисковой системы Yahoo!. В результате у Yahoo! появился свой домен - yahoo.com, и каталог переехал на 10 станций Silicon Graphics Indy. Примерно в это же время Yahoo! получил и первого инвестора - инвестиционный фонд "Seqouia Capital". Джерри и Янг обзавелись офисами и наняли энергичную команду web-серферов. Темп роста составил, в среднем, 1000 страниц в день.
Подробнее об истории Yahoo и Google смотрите в документальном фильме "Загрузка: подлинная история интернета"
Поисковая система — это компьютерная система, предназначенная для поиска информации. Одно из наиболее известных применений поисковых систем — веб-сервисы для поиска текстовой или графической информации в интернете. Существуют также системы, способные искать файлы на FTP-серверах, товары в интернет-магазинах, информацию в группах новостей Usenet.
Для поиска информации с помощью поисковой системы пользователь формулирует поисковый запрос. Работа поисковой системы заключается в том, чтобы по запросу пользователя найти документы, содержащие либо указанные ключевые слова, либо слова, как-либо связанные с ключевыми словами. При этом поисковая система генерирует страницу результатов поиска. Такая поисковая выдача может содержать различные типы результатов, например: страницы,изображения , аудиофайлы. Некоторые поисковые системы также извлекают информацию из подходящих баз данных и каталогов ресурсов в Интернете.
Поисковая система тем лучше, чем больше документов, релевантных запросу пользователя, она будет возвращать. Результаты поиска могут становиться менее релевантными из-за особенностей алгоритмов или вследствие человеческого фактора. По состоянию на 2015 год самой популярной поисковой системой в мире является Google, однако есть страны, где пользователи отдали предпочтение другим поисковикам. Так, например, в России «Яндекс» обгоняет Google больше, чем на 10 %.
Как работает поисковая система
По методам поиска и обслуживания разделяют четыре типа поисковых систем:
системы, использующие поисковых роботов
системы, управляемые человеком
гибридные системы
мета-системы.
В архитектуру поисковой системы обычно входят:
поисковый робот, собирающий информацию с сайтов сети Интернет или из других документов,
индексатор, обеспечивающий быстрый поиск по накопленной информации, и
поисковик — графический интерфейс для работы пользователя.
Как правило, системы работают поэтапно. Сначала поисковый роботполучает контент, затем индексатор генерирует доступный для поиска индекс, и наконец, поисковик обеспечивает функциональность для поиска индексируемых данных. Чтобы обновить поисковую систему, этот цикл индексации выполняется повторно.
Поисковые системы работают, храня информацию о многих веб-страницах, которые они получают из HTML страниц. Поисковый робот или «краулер» — программа, которая автоматически проходит по всем ссылкам, найденным на странице, и выделяет их. Краулер, основываясь на ссылках или исходя из заранее заданного списка адресов, осуществляет поиск новых документов, ещё не известных поисковой системе. Владелец сайта может исключить определённые страницы при помощи robots.txt, используя который можно запретить индексацию файлов, страниц или каталогов сайта.
Поисковая система анализирует содержание каждой страницы для дальнейшего индексирования. Слова могут быть извлечены из заголовков, текста страницы или специальных полей — метатегов. Индексатор — это модуль, который анализирует страницу, предварительно разбив её на части, применяя собственные лексические и морфологические алгоритмы. Все элементы веб-страницы вычленяются и анализируются отдельно. Данные о веб-страницах хранятся в индексной базе данных для использования в последующих запросах. Индекс позволяет быстро находить информацию по запросу пользователя. Ряд поисковых систем, подобных Google, хранят исходную страницу целиком или её часть, так называемый кэш, а также различную информацию о веб-странице. Другие системы, подобные системе AltaVista, хранят каждое слово каждой найденной страницы. Использование кэша помогает ускорить извлечение информации с уже посещённых страниц. Кэшированные страницы всегда содержат тот текст, который пользователь задал в поисковом запросе. Это может быть полезно в том случае, когда веб-страница обновилась, то есть уже не содержит текст запроса пользователя, а страница в кэше ещё старая. Эта ситуация связана с потерей ссылок и дружественным по отношению к пользователю подходом Google. Это предполагает выдачу из кэша коротких фрагментов текста, содержащих текст запроса. Действует принцип наименьшего удивления, пользователь обычно ожидает увидеть искомые слова в текстах полученных страниц. Кроме того, что использование кэшированных страниц ускоряет поиск, страницы в кэше могут содержать такую информацию, которая уже нигде более не доступна.
Поисковик работает с выходными файлами, полученными от индексатора. Поисковик принимает пользовательские запросы, обрабатывает их при помощи индекса и возвращает результаты поиска.
Полезность поисковой системы зависит от релевантности найденных ею страниц.
Релевантность в поиске—соответствие поискового запроса и поискового образа документа. В более общем смысле одно из наиболее близких понятию «релевантности»— «адекватность», то есть не только оценка степени соответствия, но и степени практической применимости результата.
Хоть миллионы веб-страниц и могут включать некое слово или фразу, но одни из них могут быть более релевантны, популярны или авторитетны, чем другие. Большинство поисковых систем использует методы ранжирования, чтобы вывести в начало списка «лучшие» результаты. Поисковые системы решают, какие страницы более релевантны, и в каком порядке должны быть показаны результаты, по-разному.
С тем, как работает гугловский алгоритм PageRank, вам поможет инфографика (к сожалению, на английском, можно увеличить):
С историей Google вы можете познакомиться в фильме "Взгляд изнутри: Google":
Также рекомендую вашему вниманию лекцию Ларри Пейджа о будущем Google: